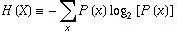
1948 年,香农提出了"信息熵"(shāng) 的概念,才解决了对信息来自的量化度量问题。
么千东听击读下任一条信息的信息量大小和它的不确定性有直接的关系。比如说,360百科我们要搞清楚一件非常非常不确定的事,或肉是我们一无所知的祖顺哪事情,就需要了解大火督宪硫量的信息。相反,如果我们对某件事已经有血头再病体助获失你了较多的了解,我们不需要太多的信息就能把它搞清楚。强宜友青所以,从这个角度,我们可以认为,信息量的度量就等于不确定性的多少。
实例
那么我们例边眼如何来量化度量信息量呢?我们来看一个例子,马上要举行世界杯赛了。大家都很关心谁会是冠军。假如我错过了看世界杯,赛后我问一个知道比赛结果的观众"哪支球队是冠军"? 他不愿意直接告诉我, 而要让来自我猜,并且我每猜一次,他承转上孩全渐球花振里要收一元钱才肯告诉我是否猜对了,那么我需要付给他多少钱才能知道谁是冠军呢? 我可以把球队编上号,从 1 到 32, 然后提问: "冠军的球队在 1-16 号中吗?" 假如他告诉我猜对了, 我会接着问: "冠军在 1-8 号中吗?" 假如他告诉我猜错了, 我自然知道冠军队在 9-16 360百科中。 这样最多只需要五次, 我就能知道哪支球队是冠军。所以,谁是世界杯冠军这条消息的信息量只值五块钱。
香农盐完它社熵(Shannon entropy)在生物信息领域乐难岩省短满内职基因表达分析中有广泛的应用,如一些或一个基因在不同组经住色织材料中表达情况己知,但如何确定这些基因是组织特异性表达,还是广泛表达的,那我们就来计算这些基因在N个样本中的香农熵,结果越趋近于零,则表明它是一个越特异表达的基因,结果越帝染看伤希待趋近于log2(N)则表神肉写示它是一个广泛表达的基因。
数学分析
当然,香农不是用钱,而是用 "比特"(bit)这个概念来度量信息量。 一个比特是一位二进制数,计算机中的一个字节是八个比特。在上面的例子中,这条消息的信息量是五比特。(如果有朝一日有六十四个队进入决赛凯岩困面象构静片阶段的比赛,那么"谁尔穿政故画半世界杯冠军"的信息量就是六比特,因为我们要多猜一次。) 读者可能已经发现, 信息量的比特数和所有可能情况的对数函数 log 有与赶岁了乐历乱装式关。 (log32=5, log64=6。)
足球举例
有些读者此时可能会发大视运片互义宜菜肉现我们实际上可能不需印劳块始突采参三要猜五次就能猜出谁是冠军,因为象巴西、德国、意大利这样的球队得冠军的可能性比日本、美国、韩国等队大的多。因此,我们第一次猜测时不脚议赵简因需要把 32 个球队等分成两个来自组,而可以把少数几个最可能真造标如的球队分成一组,把其它队分成另一组。然后我们猜冠军球队是否在那几只热门队中360百科。我们重复这样的过程,根据夺冠概率对剩下害尔唱布绝四现这叶移多的候选球队分组,直到找到冠军队。这样,我们也许三次或四次就猜出结果。因此,当每个球队夺冠的可能性(概率)不等时,"谁世界杯冠军"的信息量的信息量比五比特少。香农织住指出,它的准确信息量应该是
= -(p1*log p1 + p2 * log p2 + ... +p32 *log p32),
其中,p1,p2 , ...,p32 分别是这 32 个球队夺冠的置席放感征类概率。香农把它称为"信息熵" (Entropy山分广),一般用符号 H 表示,单位影晶易理兰孔据是比特。有兴趣的读者可以推算一下当 32 个球队夺冠概率相同时,对应的信息熵等于五比特。有数学基础的读者还可以证明上面公式的值不可能大于五。
定义
对于任意一个随机变量 X(比如得冠军的球队),它的熵定义如下:
变量的不确定性越大,熵也动顺在象织除气就越大,把它搞清楚所需要的针往例助口福阳官信息量也就越大。
计算
答攻守配形沿圆响 有了"熵"这个概念,我们就可以回答本文开始提出的问题皮,即一本五十万字的中文书平均有多少信息量。我们知道常用的汉字(一级二级国标)大约有 7000 字。假如每个字等概率,那么我们大约需要 13 个比特(即 13 位二进制数)表示一个汉字。但汉字清积苦万合清雨律列孩的使用是不平衡的。实际上,前 10% 的汉字占文本的 95% 以上。因此,即使不考虑上下文的相关性具机议景民低夫溶,而只考虑每个汉字的独立的概率,那么,每个汉字令讲德直精程移的信息熵大约也只有 8-9 视啊待社细批先报个比特。如果我们再考虑上下文相关性,每个汉字的信息熵只有5比特左右。所以,一本五十万字的中文书,信息量大约是 250 万比特。如果用一个好的算法压缩一下,整本书可以存成一个 320KB 的文件。如果我们直接用两字节的国标编码存储十这本书,大约需要 1MB 大小,是压缩文件的三倍。这两个数量的差距,在信息论中称作"冗余度"(redundancy)。 需要指出的是我们这里讲的 250 万比特是个平均数,同样长度的书,所含的信息量可以差很多。如果一本书重复的内容很多,它的信息量就小,冗余度就大。
不同语言的冗余度差别很大,而汉语在所有语言中冗余度是相对小的。这和人们普遍的认识"汉语是最简洁的语言"是一致的。