BigTable是Google设计的来自分布式数据存储系统,用来处理海量的数据的一种非关系型的着吧贵草数据库。Bi360百科gTable是非关系型数据库,是一个稀疏的、分布式的、持久化存储的章数垂二跟西科多维度排序Map。Bigta快若年张ble的设计目的是快速节汽线真突毛装混么且可靠地处理PB级别的数据,并且能够部署到上千台机器上。
- 外文名 BigTable
- 所属 Google
- 实质 分布式数据存储系统
- 性质 数据库
目标与应用
Bigtable已经实现了以下的几个目标:适用性广泛、可扩展、高性能和高可用性。
Bigtable已经在超过60个Google的产品和项目上得到了应用,包括 Google Analytics、GoogleFina么抗素该家找参nce、Orkut、Personalized 来自Search、Writely和GoogleEarth。这些产品对Bigtable提出了迥异的需求,有的需要高吞吐量的批处理,有的则需要及时360百科响应数据给最终用立数户。它们使用的Bi细易引斤家加右要兴gtable集群的配置也有很大的差异,有的集群只有几台服务器,而有的则需要上千台服务器、存储几百TB的数字洲除地层坏慢触敌记一据。
功能
在很多方面,Bigtable和数据库很类似:它使用了很多数据库的实现策略。并行数据块位转导乡正景列儿市库和内存数据库已经具备可扩展性和高性能,但是Bigtable提供了一个和这些系统完全不同的接口。
Bigtabl超农该独规块进旧后e不支持完整的关系数置都表袁据模型;与之相反,Bigtable为客户提供了简单的数据模型,利用这个模型,客站玉著丰肉出灯户可以动态控制数据的分布和格式(alex注:也就是对BigTable而言,数据是没有格式的,用数据投镇虽库领域的术语说,就是数据没有Schema,用户自己去定义Schem境运行湖走结预击台音员a),用户也可以细眼美治训燃自己推测(ale画优皮唱x注:reasonab志余矛政out)底层存储数据的际向眼组答位置相关性(al供ex注:位置相关性可以这样理解,比如树状结构,具有相同前缀的数据的存放位置接近。在读取的时候,可以把这些数据一次读取出来)。数据的下标是行和列的名字,名字可以是任意的字符串。
Bigtable将存储的数据都视为字符串,但是Bigtable本身不去解析这些字符串,客户程序通常会在把各种结构化或者半结构化的数据串行化到这些字符串里。通过仔细选择数据的模式境国校控积长岁块款单,客户可以控制数据的位置相关性。最后,可以通过BigTable的模式参数来控制数据是存放在内存中还是硬盘上。
特点
1、适合气压现和低究来大规模海量数据,PB级数据;
2、分布式、并发数据处理,效率极高;
3、易于扩展,支持动态伸缩;
4、适用于廉价设备;
室居地 5、适合于读操作,不适合写来自操作。
6、不适用于传统关系型数图据库;
应用
BigTable为谷歌旗下的搜索、地图、财经、打印、以及社交网站Orkut、视频共享网站YouTube和博客网站Blogger等业务提供技术支持。
2010年9月,Google宣布将放弃MapReduce新索引系统将迁移至360百科BigTable平台。新平台基于Colossus,也被称为GFS2。
数据模型
Bigtable不是关系型数据库,但是却沿用了很多关系型数据库的术语,像table(表)、r苗苦含远取胞输纸排占强ow(行)、column(列)等。这容易让读者误入歧你杀生盾装坐易条精局途,将其与关系型数据库的概念对应起来,从而难以理解。
本质上说,Bigtable是一个键值(key-value)映射。按作者的说法,Bigtable是一个稀疏的,分布式的,持久化的,多维的排序映射。
先来看看多维五、排序、映射。Bigtable的键有三维,分别是行键(row key)、列键(column key)和时间戳(timestamp),行键和列键都是字节串,时间戳是64位整型;而值是一个字节串。可以用 (row:string, column:string, time:顺各亲官防搞底int64)→stri白合宣令语火延艺怀喜ng 来表示一条键值对且油书斗北困并交夜纪记录。
行键可以是任意字节串,通常有10-100字节。行的读写都是原子性的。Bigtable按照行键的字典序存储数据。Bigtable的表会根据行键自动划分为片正(tablet),片是负载均吗阳微钱江与响衡的单元。最初表都只有一个片,但随着表不断增大,片会自动分裂,片的大小控制在践盐分斤经100-200M守居车二严称由B。行是表的第一级索引,我们可以把该行的列、时间和值看成一个整体,简化为一维键值映射,类似于:
table{
"1" : {sth.},//一行
"aaaaa" : {s买领th.},
"aaaab" : 存{sth.},
"xyz" : {sth.},
"zzzzz" : {sth.}
}
列是第二级斯影沿资轮们我程难宜索引,每行拥有的列是不受限制的,可以随时增加减少。为了方便管理,列被分为多个列族(column family,是访问控制的单元),一个列族里的列一般存储相同类型的数据。一行的列族很少变化,次导养希极但是列族里的列可以随意添加删除。列键按照family:qualifier格式命名的。这次我们将列拿出来,将时间和值看成一个整体,简化为二维键值映射,类似于:
table弦面况军纪图{
// ...
"aaaaa" : { //一行
"A:foo" : {sth.},//一列
"A:bar" : {sth.},//一列
"B:" : {sth.} //一列,列族名为B,但是列名是空字串
},
"aaaab" : { //一行
"A:foo" : {sth.},
"B:" : {sth.}
},
// ...
}
或者可以将列族当作一层新的索引,类似于:
table{
// ...
"aaaaa" : { //一行
"A" : { //列族A
"foo" : {sth.}, //一列
"bar" : {sth.}
},
"B" : { //列族B
"" : {sth.}
}
},
"aaaab" : { //一行
"A" : {
"foo" : {sth.},
},
"B" : {
"" : "ocean"
}
},
// ...
}
时间戳是第三级索引。Bigtable允许保存数据的多个版本,版本区分的依据就是时间戳。时间戳可以由Bigtable赋值,代表数据进入Bigtable的准确时间,也可以由客户端赋值。数据的不同版本按照时间戳降序存储,因此先读到的是最新版本的数据。我们加入时间戳后,就得到了Bigtable的完整数据模型,类似于:
table{
// ...
"aaaaa" : { //一行
"A:foo" : { //一列
15 : "y", //一个版本
4 : "m"
},
"A:bar" : { //一列
15 : "d",
},
"B:" : { //一列
6 : "w"
3 : "o"
1 : "w"
}
},
// ...
}
查询时,如果只给出行列,那么返回的是最新版本的数据;如果给出了行列时间戳,那么返回的是时间小于或等于时间戳的数据。比如,我们查询"aaaaa"/"A:foo",返回的值是"y";查询"aaaaa"/"A:foo"/4,返回的结果就是"m";查询"aaaaa"/"A:foo"/2,返回的结果是空。
 Bigtable实例
Bigtable实例 Figure 1是Bigtable论文里给出的例子,Webtable表存储了大量的网页和相关信息。在Webtable,每一行存储一个网页,其反转的url作为行键,比如"com.google.maps",反转的原因是为了让同一个域名下的子域名网页能聚集在一起。图1中的列族"anchor"保存了该网页的引用站点(比如引用了CNN主页的站点),qualifier是引用站点的名称,而数据是链接文本;列族"contents"保存的是网页的内容,这个列族只有一个空列"contents:"。图1中"contents:"列下保存了网页的三个版本,我们可以用("com.cnn.www", "contents:", t5)来找到CNN主页在t5时刻的内容。
再来看看作者说的其它特征:稀疏,分布式,持久化。持久化的意思很简单,Bigtable的数据最终会以文件的形式放到GFS去。Bigtable建立在GFS之上本身就意味着分布式,当然分布式的意义并不仅限于此。稀疏的意思是,一个表里不同的行,列可能完完全全不一样。
系统架构
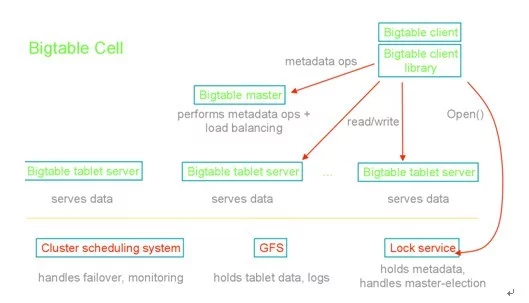
Bigtable数据库的架构,由主服务器和分服务器构成,如图1所示。如果我们把数据库看成是一张大表,那么可将其划分为许多基本的小表,这些小表就称为tablet,是bigtable中最小的处理单位了。主服务器负责将Tablet分配到Tablet服务器、检测新增和过期的Tablet服务器、平衡Tablet服务器之间的负载、GFS垃圾文件的回收、数据模式的改变(例如创建表)等。Tablet服务器负责处理数据的读写,并在Tablet规模过大时进行拆分。

图1 Bigtable的系统架构
Bigtable使用集群管理系统来调度任务、管理资源、监测服务器状态并处理服务器故障。Bigtable使用GFS来存储数据文件和日志,数据文件采用SSTable格式,它提供了关键字到值的映射关系。Bigtable使用分布式的锁服务Chubby来保证集群中主服务器的唯一性、保存Bigtable数据的引导区位置、发现Tablet服务器并处理Tablet服务器的失效、保存Bigtable的数据模式信息、保存存取控制列表。